专注Java教育14年
全国咨询/投诉热线:444-1124-454
更新时间:2022-11-18 14:49:15 来源:赢咖4 浏览1082次
我们将构建一个使用 BFS 算法遍历网页的网络爬虫。
爬虫将从访问包含的每个 URL 的源 URL 开始。访问此源 URL 中的每个 URL 后,该算法将访问子 URL 中的每个 URL 并向下访问链,直到它到达您将指定的断点。
该算法将仅访问以前未访问过的 URL,以确保我们不会循环访问。这些 URL 代表顶点,URL 之间的连接是边。
首先将根 URL 添加到队列和已访问 URL 列表。
当队列不为空时,从队列中删除 URL 并读取其原始 HTML 内容。
在读取 URL 的 HTML 内容时,搜索父 HTML 中包含的任何其他 URL。
当找到新的 URL 时,通过检查已访问的 URL 列表来验证它以前没有被访问过。
将新找到的未访问 URL 添加到队列和已访问 URL 列表中。
对在 HTML 内容中找到的每个新 URL 重复步骤 4 和 5。
找到 HTML 中的所有 URL 后,从步骤 2 开始重复,直到程序到达您指定的断点。
使用名称创建一个 Java 类WebCrawler并将以下代码添加到文件中:
public class WebCrawler {
private Queue<String> urlQueue;
private List<String> visitedURLs;
public WebCrawler() {
urlQueue = new LinkedList<>();
visitedURLs = new ArrayList<>();
}
}
在上面的代码中,我们已经初始化了我们随后将要使用的类、数据结构和构造函数。
public void crawl(String rootURL, int breakpoint) {
urlQueue.add(rootURL);
visitedURLs.add(rootURL);
while(!urlQueue.isEmpty()){
// remove the next url string from the queue to begin traverse.
String s = urlQueue.remove();
String rawHTML = "";
try{
// create url with the string.
URL url = new URL(s);
BufferedReader in = new BufferedReader(new InputStreamReader(url.openStream()));
String inputLine = in.readLine();
// read every line of the HTML content in the URL
// and concat each line to the rawHTML string until every line is read.
while(inputLine != null){
rawHTML += inputLine;
inputLine = in.readLine();
}
in.close();
} catch (Exception e){
e.printStackTrace();
}
// create a regex pattern matching a URL
// that will validate the content of HTML in search of a URL.
String urlPattern = "(www|http:|https:)+[^\s]+[\\w]";
Pattern pattern = Pattern.compile(urlPattern);
Matcher matcher = pattern.matcher(rawHTML);
// Each time the regex matches a URL in the HTML,
// add it to the queue for the next traverse and the list of visited URLs.
breakpoint = getBreakpoint(breakpoint, matcher);
// exit the outermost loop if it reaches the breakpoint.
if(breakpoint == 0){
break;
}
}
}
在该crawl()方法中,rootURL是爬虫的起点,breakpoint代表您希望爬虫发现多少个 URL。
该算法涉及的步骤是:
该算法首先将根 URL 添加到队列和已访问 URL 列表。
BufferedReader它使用API读取 URL 的每一行 HTML 内容。
然后,它在读取rawHTML变量时连接每个 HTML 行。
private int getBreakpoint(int breakpoint, Matcher matcher) {
while(matcher.find()){
String actualURL = matcher.group();
if(!visitedURLs.contains(actualURL)){
visitedURLs.add(actualURL);
System.out.println("Website found with URL " + actualURL);
urlQueue.add(actualURL);
}
// exit the loop if it reaches the breakpoint.
if(breakpoint == 0){
break;
}
breakpoint--;
}
return breakpoint;
}
上面的代码执行以下操作:
该getBreakPoint方法使用指定的正则表达式模式来发现rawHTML.
这些操作会不断迭代,直到爬虫发现了您的breakpoint.
以下是应用程序主要方法的片段:
public static void main(String[] args) {
WebCrawler crawler = new WebCrawler();
String rootURL = "https://www.section.io/engineering-education/springboot-antmatchers/";
crawler.crawl(rootURL, 100);
}
下面是运行该程序的输出快照:
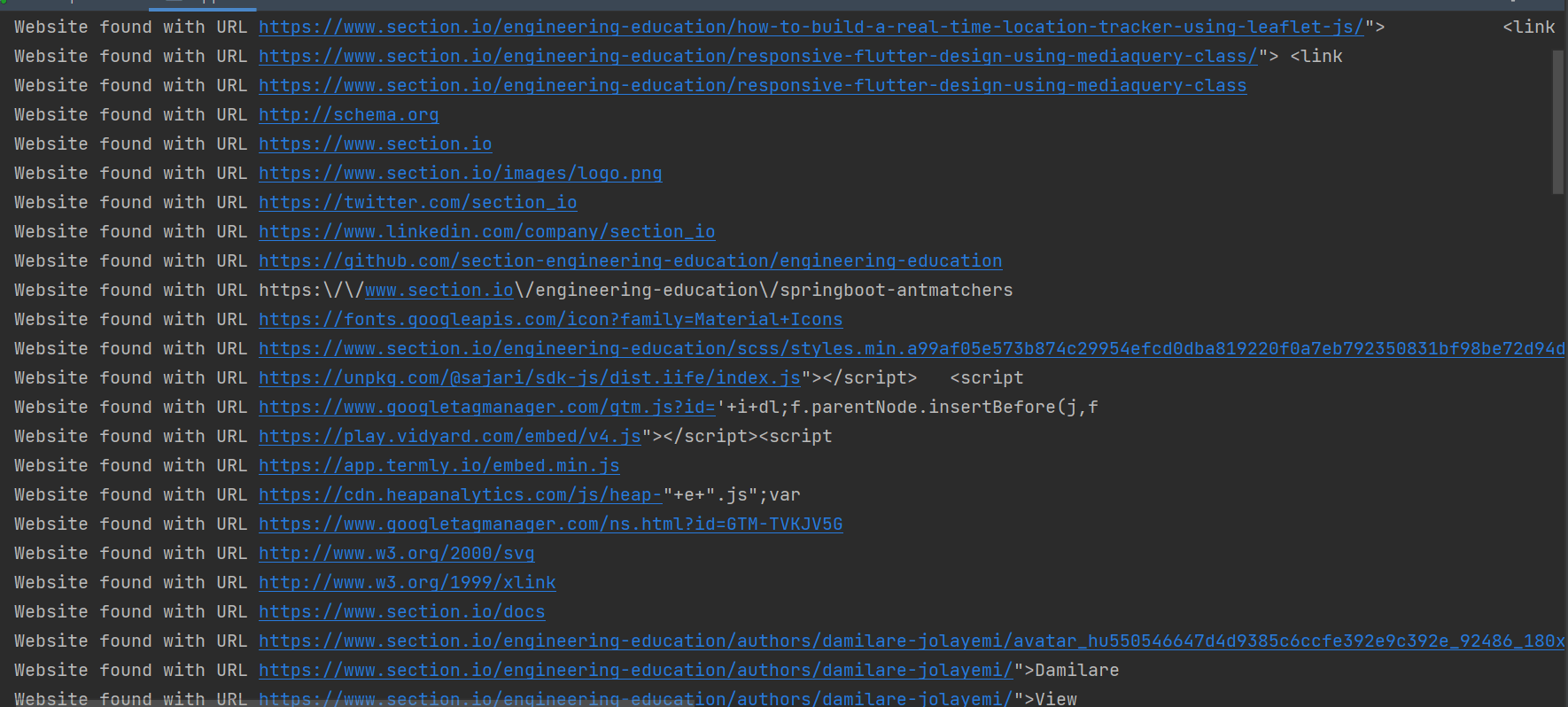
上面快照中的 URL 是网络爬虫从根 URL 开始通过嵌入 URL 爬取到断点的所有网页中包含的一些 URL。如果大家想了解更多相关知识,不妨来关注一下本站的Java赢咖4在线学习,里面的课程内容从入门到精通,细致全面,通俗易懂,很适合没有基础的小伙伴学习,希望对大家能够有所帮助。
 Java实验班
Java实验班
0基础 0学费 15天面授
 Java就业班
Java就业班
有基础 直达就业
 Java夜校直播班
Java夜校直播班
业余时间 高薪转行
 Java在职加薪班
Java在职加薪班
工作1~3年,加薪神器
 Java架构师班
Java架构师班
工作3~5年,晋升架构
提交申请后,顾问老师会电话与您沟通安排学习

官方微信

官方抖音
















