专注Java教育14年
全国咨询/投诉热线:444-1124-454
更新时间:2021-11-22 10:50:24 来源:赢咖4 浏览1559次
很多小伙伴对Redis同步数据库的实现方法不是很了解,小编来为大家讲解一下,Redis的主从同步机制可以确保redis的master和slave之间的数据同步。
同步方式包括:全量复制和增量复制
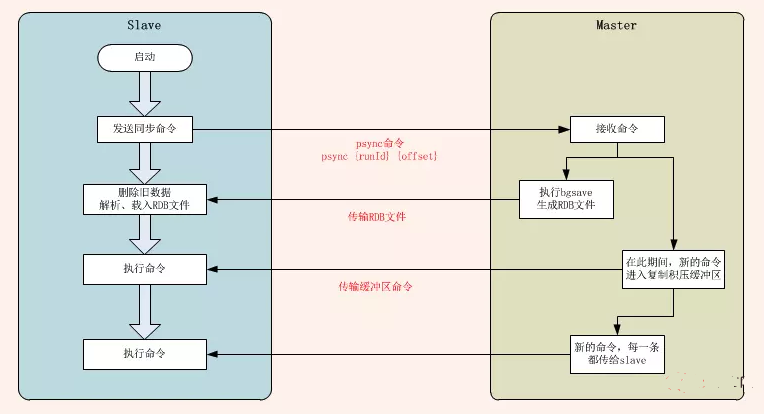
slave第一次启动时,连接Master,发送PSYNC命令,格式为psync {runId} {offset}{runId} 为master的运行id;{offset}为slave自己的复制偏移量。
slave第一次连接master时,slave并不知道master的runId,也不知道自己偏移量,这时候slave会传一个问号和-1,告诉master节点是第一次同步。格式为psync ? -1
当master接收到psync ? -1时,知道slave是要全量复制,就会将自己的runId和offset告知slave,回复命令fullresync {runId} {offset}。同时,master会执行bgsave命令来生成rdb文件,期间的所有写命令将被写入缓冲区。slave接受到master的回复命令后,会保存master的runId和offset,slave此时处于同步状态。
slave处于同步状态,如果此时收到请求,当配置参数slave-server-stale-data yes时,会响应当前请求;slave-server-stale-data no,返回错误。
master bgsave执行完毕,向slave发送rdb文件。rdb文件发送完毕后,开始向slave发送缓冲区中的写命令。
slave收到rdb文件,丢弃所有旧数据,开始载入rdb文件。
rdb文件同步结束之后,slave执行从master缓冲区发送过来的所以写命令。
此后 master 每执行一个写命令,就向slave发送相同的写命令。
如果出现网络闪断或者命令丢失等异常情况时,当主从连接恢复后,由于从节点之前保存了自身已复制的偏移量和主节点的运行ID。因此会把它们当作psync参数发送给主节点,要求进行部分复制操作,格式为psync {runId} {offset}。
主节点接到psync命令后首先核对参数runId是否与自身一致,如果一致,说明之前复制的是当前主节点;之后根据参数offset在自身复制积压缓冲区查找,如果偏移量之后的数据存在缓冲区中,则对从节点发送+continue响应,表示可以进行部分复制;否则进行全量复制。
主节点根据偏移量把复制积压缓冲区里的数据发送给从节点,保证主从复制进入正常状态。
通过上述介绍,相信大家对Redis同步数据库的实现方法已经有所了解,大家如果想了解更多相关知识,不妨来关注一下赢咖4的Java赢咖4在线学习,里面的内容丰富,从浅到深,适合没有基础的小伙伴学习,希望对大家能够有所帮助。
 Java实验班
Java实验班
0基础 0学费 15天面授
 Java就业班
Java就业班
有基础 直达就业
 Java夜校直播班
Java夜校直播班
业余时间 高薪转行
 Java在职加薪班
Java在职加薪班
工作1~3年,加薪神器
 Java架构师班
Java架构师班
工作3~5年,晋升架构
提交申请后,顾问老师会电话与您沟通安排学习

官方微信

官方抖音
















